Bulik-Sullivan, B., Finucane, H. K., Anttila, V., Gusev, A., Day, F. R., Loh, P. R., … & Neale, B. M. (2015). An atlas of genetic correlations across human diseases and traits. Nature genetics, 47(11), 1236-1241.
The LD score, a per SNP measure of the size of the part of the genome tagged by SNP j:
\[l_i\]
Parameters
\[ b = \frac{\sqrt{N_{1} N_{2}} * cov_g}{M} = slope\]
\[ a = \frac{cor_p * N_s}{\sqrt{N_{1} N_{2}}} + a = intercept\]
Works for GWAS that do not overlap!
BUT!
Its a regression where the “outcome” (GWAS results) and the “predictor” (LD score) come form different sources…
That’s really weird… and it puts a little bit of responsibility on the user to ensure the variables are from a common population…
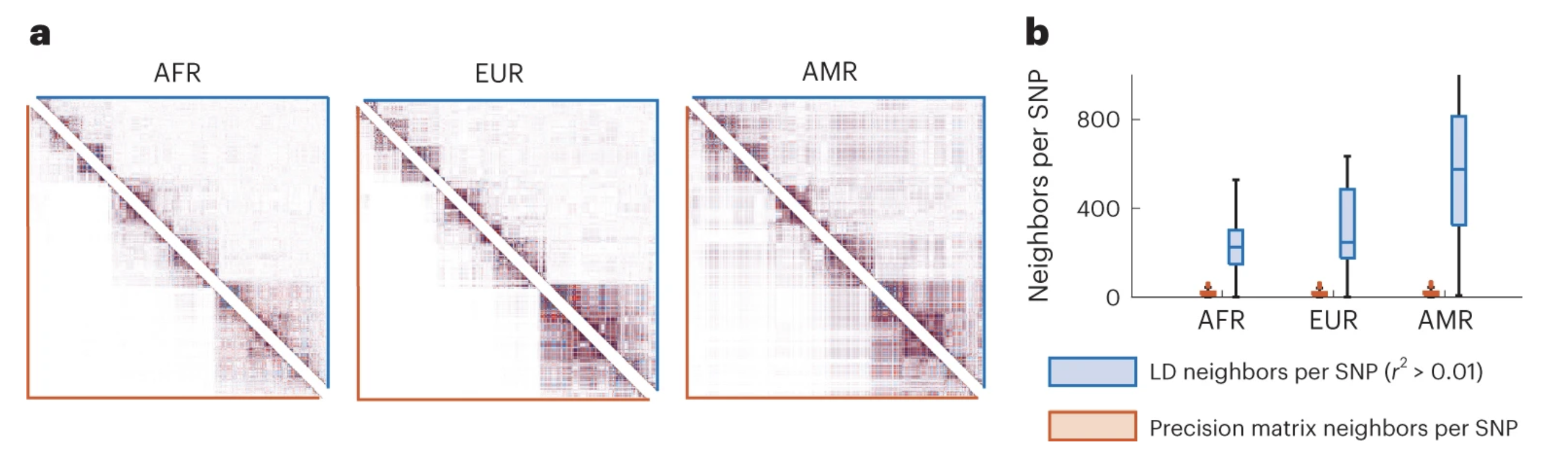
A look at variation in the LD map
Salehi Nowbandegani, P., Wohns, A. W., Ballard, J. L., Lander, E. S., Bloemendal, A., Neale, B. M., & O’Connor, L. J. (2023). Extremely sparse models of linkage disequilibrium in ancestrally diverse association studies. Nature Genetics, 55(9), 1494-1502.
So we want to match ancestry in the LDscore to the GWAS sample